
This tutorial explains how to automate a login with Scrapy FormRequest.
Using regular Scraping methods will get you quite far on their own, but sooner or later you’ll face the obstacle of Login pages. Often there may be data you want to scrape, but its not available unless you have an account and it’s logged in.
By default of course, Scrapy approaches the website in a “not logged in” state (guest user). Luckily, Scrapy offers us the Formrequest feature with which we can easily automate a login into any site, provided we have the required data (password, username, email etc.).
Formdata for Scrapy FormRequest
In this FormRequest example we’ll be scraping the quotes.toscrape site. One of the first things we’re going to do is to scout the site and learn about how it handles login data.
To put it simply, in order to create an automated login, we need to know what fields (data) a site requires in order for a successful login. Each site has unique fields that you must discover by simulating the login process yourself and observing the data being sent.
Visit the site, and before doing anything open the inspect tool by right clicking and selecting it, or use the shortcut CLTR + SHIFT + I. Next navigate to the Network tab. This should begin recording any network activity like logins for you to see.
(This tutorial is done on chrome, but can be followed on any browser with an inspect tool)
Finally login using a random name and password (you don’t need an account). Some files should appear in the Network tab that you’ve opened. These contain the data we need to see. If you’ve done everything right up to now, you’re screen should be looking like this.
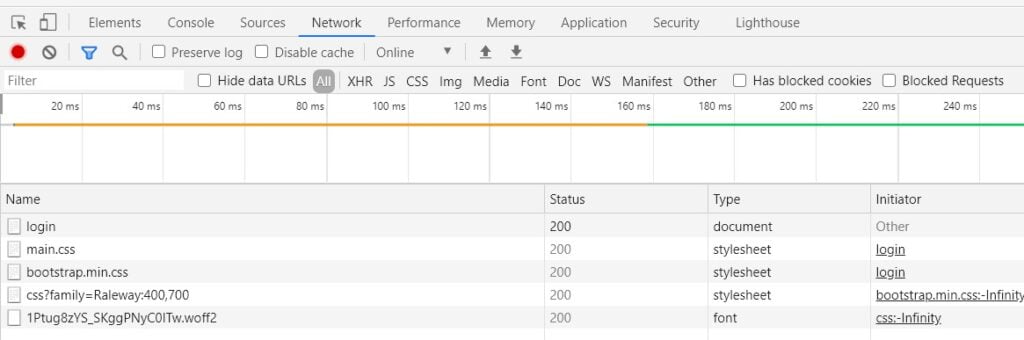
The data we need is within the “login” file. Click on it to reveal it’s contents. You should be seeing something like the image below.
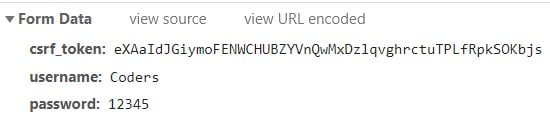
The username and password above are we used to login. csrf_token is a hidden field for authentication purposes that prevents us from just logging indiscriminately. If we hadn’t use this method to locate this field and it’s value, we would never have been able to login even with just the username and password.
Now that we have the data we need, it’s time to begin the coding.
Scrapy FormRequest Example
We’re going to create two separate functions here. The first one called parse is called automatically on the start_url we defined. Be sure to link the start_url or request directly to the login page of the site you’re targeting.
In the parse function we basically retrieve the value of the csrf_token and pass it into the FormRequest function, along with the username and password we used earlier.
class ScrapySpider(CrawlSpider):
name = 'login'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/login']
def parse(self,response):
csrf_token = response.xpath('//*[@name="csrf_token"]/@value').extract_first()
print(csrf_token)
yield scrapy.FormRequest.from_response(response, formdata={'csrf_token': csrf_token, 'username':'Coders', 'password': '12345'}, callback=self.parse_after_login)
def parse_after_login(self,response):
print(response.xpath('.//div[@class = "col-md-4"]/p/a/text()'))
The important thing to note is that we’ve linked the FormRequest to another function called parse_after_login. This function is responsible for handling all the actions that take place after the login is successful.
We’ve included a single line in this new function that we’re using as a check to see if the login was successful or not. From our observations, the website says “login” in a certain element if you are not already logged. Similarly, if you’re logged in, it will say “logout”. This line prints out that value to check the status of our login.
We have another alternative technique for using FormRequest, discussed at the end of the tutorial, which you may find more convenient. Be sure to give it a read as well.
Login with FormRequest – Guidelines
One of the reasons why Web scraping is so difficult and complex is that there’s no one magic solution that works on all websites. Each Spider needs to be tailored specifically to deal with a single site. However, the general idea and concept usually remains the same, as described below.
- Scout the log in page of the site you’re targeting. Replicate the login procedure and note down the “Form Data” fields and values. Keep an eye out for hidden fields in particular.
- Connect to the login page of the site using your Spider.
- Create the appropriate functions for parsing and include the Scrapy FormRequest using the form data that we gathered earlier.
- Make sure to match your key fields (for form data) with the key fields that the website uses (e.g username, user, password and pass). Variation can be expected after all.
- Include a little check to make sure that you’ve logged in correctly. Compare the “before login” and “after login” page of the site and look for something that changes. That change will help you identify whether you’ve logged in correctly.
- Once you’ve successfully passed the previous steps, you can now include the actual parse function for the data that you want to scrape off the site. You can now use the regular Scrapy techniques like link following, link extraction, rules etc.
Alternative
This is an alternative technique that you can use to skip out the “Form data” step.
What the below program does is to automatically extract all the hidden fields from Form data and add them into the formdata variable we’re going to pass into Formrequest.
In short, inputs contains the form data that we extracted from the site. We iterate over it, adding each field separately into formdata. Once that’s done, we set our password and username and submit formdata into FormRequest along with the necessary data.
class ScrapySpider(CrawlSpider):
name = 'login'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/login']
def parse(self, response):
inputs = response.css('form input')
print(inputs)
formdata = {}
for input in inputs:
name = input.css('::attr(type)').get()
value = input.css('::attr(value)').get()
formdata[name] = value
formdata['username'] = 'YOUR_USERNAME'
formdata['password'] = 'YOUR_PASSWORD'
return scrapy.FormRequest.from_response(
response,
formdata = formdata,
callback = self.parse_after_login
)
def parse_after_login(self, response):
print(response.xpath('.//div[@class = "col-md-4"]/p/a/text()').get())
The rest of the program has the same function as previous example.
This marks the end of the Scrapy Login with FormRequest tutorial. Any suggestions or contributions for CodersLegacy are more than welcome. Questions regarding the article content can be asked in comments section below.
I want to design a form that has multiple radio buttons that are not related to each other. Like a few radio buttons to choose the car brand and a few radio buttons to choose the color and a few radio buttons to choose the model. How to make this form?
If you want to do it in Python, then you can use a GUI library like Tkinter or PyQt6.