
Excel files often contain multiple sheets, each representing different aspects of data. When working with such files in Python, it is crucial to know how to extract and analyze data from specific sheets. This tutorial will demonstrate how to read Excel files with multiple sheets using Pandas, a Python library.
- The read_excel() method:
- Specifying the file path to read an Excel file in Python Pandas:
- Reading all the sheets of an Excel file in Python Pandas:
- Reading a single sheet of an Excel file in Python Pandas:
- Assigning new labels when reading an Excel file:
- Selecting specific columns when reading an Excel file:
- Changing the index when reading an Excel file:
The read_excel() method:
read_excel() allows us to load an entire Excel file or select specific sheets, columns, or rows of interest. It takes io as a parameter, which specifies the file path of the Excel file, and returns a Pandas DataFrame or a dictionary of Pandas DataFrames depending on the parameters passed to it. Furthermore, it also accepts many other optional parameters such as sheet_name, names, usecols, etc. We will discuss these in more detail later.
Specifying the file path to read an Excel file in Python Pandas:
As stated above, the io parameter accepts file paths as values. These paths can be any valid strings, URLs, or even path objects. Simply pass the full path of your Excel file into the method.
We will use an Excel file titled “ExcelSample.xlsx”. The file contains one sheet titled “Sheet1” and its contents are shown below.
Sheet1:
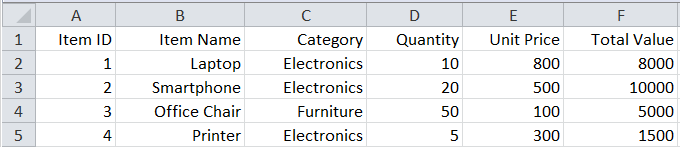
Example 1:
“ExcelSample.xlsx” is stored in Local Disk E, inside the Coders Legacy and Pandas folders. Thus, its file path will be “E:/Coders Legacy/Pandas/ExcelSample.xlsx” which we will pass into read_excel().
import pandas as pd
df = pd.read_excel("E:/Coders Legacy/Pandas/ExcelSample.xlsx")
print(df)
Output:
Item ID Item Name Category Quantity Unit Price Total Value
0 1 Laptop Electronics 10 800 8000
1 2 Smartphone Electronics 20 500 10000
2 3 Office Chair Furniture 50 100 5000
3 4 Printer Electronics 5 300 1500After printing the contents of the DataFrame, we can see that all the contents of the Excel file were successfully copied.
Example 2:
However, if we do not wish to pass the entire path (as sometimes they can be quite long), you can use the os module to get the current working directory and then add the name of the file to get the full path of the Excel file. Let’s go over this in more detail.
First, import the os module. Then, use the os.path.dirname() method and pass __file__ as a parameter to receive the path of the current directory and store that in a variable. After that, use the os.path.join() method to join the filename with the current directory’s path and pass the returned value to the read_excel() method.
import pandas as pd
import os
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath)
print(df)
Output:
Item ID Item Name Category Quantity Unit Price Total Value
0 1 Laptop Electronics 10 800 8000
1 2 Smartphone Electronics 20 500 10000
2 3 Office Chair Furniture 50 100 5000
3 4 Printer Electronics 5 300 1500As expected, this output is the same as the previous example. cdir contained the path to the current directory, and fpath contained the path to the Excel file.
Potential Errors:
Note that you may encounter errors if your software is not properly up-to-date. One potential error is:
ImportError: Missing optional dependency 'openpyxl'. Use pip or conda to install openpyxl.If you encounter this error, open the command prompt and type the following command:
pip install openpyxl --upgradeAfter the command prompt finishes installing the new packages, restart your IDE and run your code again.
Reading all the sheets of an Excel file in Python Pandas:
If the Excel files contain multiple sheets with relevant data, it may sometimes be necessary to read all of it using Python Pandas. Previously, we stated that the read_excel() method could return a dictionary of DataFrames if certain conditions were met. We will now explore this in more detail.
The aforementioned conditions involve assigning None to the sheet_name parameter which we mentioned earlier. sheet_name is used to specify which sheet should be selected. It accepts strings, integers, and lists as values and its default value is 0 which refers to the first sheet. It uses integers for sheet-based zero-indexing. By passing None, we can request a dictionary containing all the DataFrames of each sheet, with the key being the sheet name/index and the value being the DataFrame.
We will add another sheet, titled “Sheet2” into “ExcelSample.xlsx”. The contents of the Excel file will now be:
Sheet1:
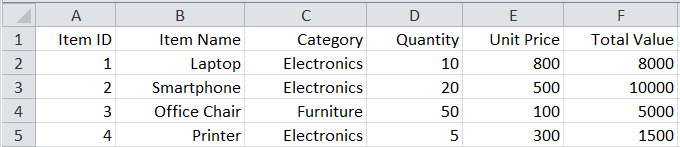
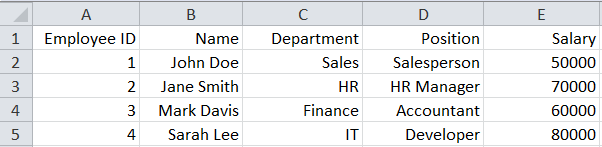
Sheet2:
Example:
By passing the file path of “ExcelSample.xlsx” and assigning None to sheet_name, we should now receive a dictionary containing two DataFrames. “Sheet1” and “Sheet2” will be the keys and their respective contents will be the values.
We will also be making use of the pprint module to make our output look more presentable.
import os
from pprint import pprint
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath, sheet_name = None)
pprint(df)
Output:
{'Sheet1': Item ID Item Name Category Quantity Unit Price Total Value
0 1 Laptop Electronics 10 800 8000
1 2 Smartphone Electronics 20 500 10000
2 3 Office Chair Furniture 50 100 5000
3 4 Printer Electronics 5 300 1500,
'Sheet2': Employee ID Name Department Position Salary
0 1 John Doe Sales Salesperson 50000
1 2 Jane Smith HR HR Manager 70000
2 3 Mark Davis Finance Accountant 60000
3 4 Sarah Lee IT Developer 80000}Reading a single sheet of an Excel file in Python Pandas:
Python Pandas also allows us to read one specific sheet from Excel files containing multiple sheets by passing the name of the sheet to sheet_name. The sheet_name parameter’s behavior has already been discussed in the previous section so let’s directly move on to the applications.
For this section, we’ll also add another sheet named “Sheet3” to “ExcelSample.xlsx”. The Excel file now contains:
Sheet1:
Sheet2:
Sheet3:
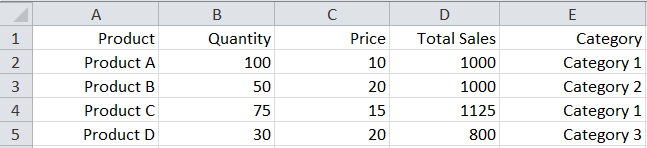
Example 1:
Now, we’ll use read_excel() to read from the Excel file while specifying “Sheet2” as the desired output.
import os
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath, sheet_name = "Sheet2")
print(df)
Output:
Employee ID Name Department Position Salary
0 1 John Doe Sales Salesperson 50000
1 2 Jane Smith HR HR Manager 70000
2 3 Mark Davis Finance Accountant 60000
3 4 Sarah Lee IT Developer 80000Example 2:
sheet_name also accepts lists as values. This allows us to obtain a dictionary containing all the DataFrames specified through the list. First, we’ll demonstrate this with a list of strings. These strings will be the sheet names of the Excel file.
import os
from pprint import pprint
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath, sheet_name = ["Sheet2", "Sheet3"])
pprint(df)
Output:
{'Sheet2': Employee ID Name Department Position Salary
0 1 John Doe Sales Salesperson 50000
1 2 Jane Smith HR HR Manager 70000
2 3 Mark Davis Finance Accountant 60000
3 4 Sarah Lee IT Developer 80000,
'Sheet3': Product Quantity Price Total Sales Category
0 Product A 100 10 1000 Category 1
1 Product B 50 20 1000 Category 2
2 Product C 75 15 1125 Category 1
3 Product D 30 20 800 Category 3}Example 3:
Next, we’ll pass a list of integers. 0 refers to the first sheet, 1 refers to the second sheet, and so on. Let’s try to obtain the same output as the previous example using a list of integers.
import os
from pprint import pprint
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath, sheet_name = [1, 2])
pprint(df)
Output:
{1: Employee ID Name Department Position Salary
0 1 John Doe Sales Salesperson 50000
1 2 Jane Smith HR HR Manager 70000
2 3 Mark Davis Finance Accountant 60000
3 4 Sarah Lee IT Developer 80000,
2: Product Quantity Price Total Sales Category
0 Product A 100 10 1000 Category 1
1 Product B 50 20 1000 Category 2
2 Product C 75 15 1125 Category 1
3 Product D 30 20 800 Category 3}As expected, the outputs of the current and previous examples are the same.
Example 4:
We can also pass a list containing both integers and strings. This works similarly to the previous examples except now we are using both data types as inputs for sheet_name.
Let’s test this by printing the first sheet and the sheet titled “Sheet3”.
import os
from pprint import pprint
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath, sheet_name = [0, "Sheet3"])
pprint(df)
Output:
{0: Item ID Item Name Category Quantity Unit Price Total Value
0 1 Laptop Electronics 10 800 8000
1 2 Smartphone Electronics 20 500 10000
2 3 Office Chair Furniture 50 100 5000
3 4 Printer Electronics 5 300 1500,
'Sheet3': Product Quantity Price Total Sales Category
0 Product A 100 10 1000 Category 1
1 Product B 50 20 1000 Category 2
2 Product C 75 15 1125 Category 1
3 Product D 30 20 800 Category 3}Assigning new labels when reading an Excel file:
To change the labels from the default values, we will need to familiarize ourselves with two new parameters; header and names.
header is used to specify the column headings of the DataFrame. It accepts an integer or list of integers as values and its default value is 0 which indicates that the first row should be used to make the labels. It follows row-based zero-indexing. 0 refers to the first row and 1 refers to the second row and so forth.
Additionally, the DataFrame will only be created using the header row and all rows after it. This means that passing header=3 will cause it to skip the first 3 rows of the DataFrame and only use the remaining rows as data.
names defines the new column labels to be used for the DataFrame. It accepts array-like objects as values and is None by default.
Example 1:
Let’s try using the third row for the labels.
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath, header = 2)
print(df)
Output:
2 Smartphone Electronics 20 500 10000
0 3 Office Chair Furniture 50 100 5000
1 4 Printer Electronics 5 300 1500Note that the first and second rows of the Excel file were completely ignored and not stored in the contents of the DataFrame.
Example 2:
Having explained header, we will now proceed to change the default labels to our own custom labels. To do this, we first need to assign None to the header parameter so that we can confirm that no headers are required. Then, we will assign a list containing the new labels to the names parameter.
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath, header = None, names = ["A", "B", "C", "D", "E", "F"])
print(df)
Output:
A B C D E F
0 Item ID Item Name Category Quantity Unit Price Total Value
1 1 Laptop Electronics 10 800 8000
2 2 Smartphone Electronics 20 500 10000
3 3 Office Chair Furniture 50 100 5000
4 4 Printer Electronics 5 300 1500Using this technique, we managed to assign our own custom labels to the DataFrame without compromising the contents of the Excel file. If the labels of the Excel file were not predefined, then we can define them with this technique.
Selecting specific columns when reading an Excel file:
usecols outlines which columns should be parsed and stored in the DataFrame. It accepts a string or a list of strings or integers and its default value is None which means that it will parse all the columns.
If we want to refer to the columns using the Excel file’s original column labels, we will pass a string. This means we will use the default “A”, “B”, “C” headings to specify which columns we want to parse.
But if we want to use the columns of the newly created DataFrame, we must pass a list of strings or integers. The strings will be the new column labels and the integers will be the index of the column (zero-indexing is used). Be careful not to pass a list containing both strings and integers since only one type is allowed.
For your convenience, the image of “Sheet1” (the default Sheet) has been reposted below.
Example 1:
First, let’s show how to use a single string. For this example, we’ll parse column “A” and column “E” only. As we can see, “A” corresponds to “Item ID” while “E” corresponds to “Unit Price”. Both must be passed using a single string with a comma separating them.
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath, usecols = "A, E")
print(df)
Output:
Item ID Unit Price
0 1 800
1 2 500
2 3 100
3 4 300Moreover, we could have passed “A : E” to include all the columns between “A” and “E” too.
Example 2:
Now let’s move on to passing a list of strings. Keep in mind that these strings must be column labels that currently exist in the DataFrame. Let’s retrieve the “Item ID”, “Category” and “Total Value” columns.
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath, usecols = ["Item ID", "Category", "Total Value"])
print(df)
Output:
Item ID Category Total Value
0 1 Electronics 8000
1 2 Electronics 10000
2 3 Furniture 5000
3 4 Electronics 1500Example 3:
Finally, we will use a list of integers to parse the “Quantity” and “Unit Price” columns. The first column’s index is 0 so we will pass 3 and 4 to acquire the “Quantity” and “Unit Price” columns.
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath, usecols = [3, 4])
print(df)
Output:
Quantity Unit Price
0 10 800
1 20 500
2 50 100
3 5 300Changing the index when reading an Excel file:
index_col sets the index of the DataFrame by specifying which column or columns should be used as the index. It accepts an integer or a list of integers and is None by default. It follows column-based zero-indexing to choose the column we wish to use as an index.
Example:
To demonstrate, we’ll assign the first column of the Excel file as the index by passing 0 to index_col.
cdir = os.path.dirname(__file__)
fpath = os.path.join(cdir, "ExcelSample.xlsx")
df = pd.read_excel(fpath, index_col = 0)
print(df)
Output:
Item Name Category Quantity Unit Price Total Value
Item ID
1 Laptop Electronics 10 800 8000
2 Smartphone Electronics 20 500 10000
3 Office Chair Furniture 50 100 5000
4 Printer Electronics 5 300 1500This marks the end of the “How to read Excel files with Multiple Sheets in Python Pandas” Tutorial. Any suggestions or contributions for CodersLegacy are more than welcome. Questions regarding the tutorial content can be asked in the comments section below.