
Python Urllib as the name implies is a Python library made to deal with URL’s.
The Python Urllib library consists of multiple modules, each which has a set of functions for a specific task. We’ll be covering the three modules listed below.
- Urllib.request – For opening connections to URL’s
- Urllib.parse – For interacting with and parsing URL’s.
- Urllib.error – For dealing with errors.
There is another similar library, called the “requests library” which was released as a more cleaner and improved version of urllib. You might want to consider learning it instead.
Urllib Request
This is the Urllib module incharge of accessing or “opening” URLs.
Using the urlopen() function from the urllib request library, we can establish a connection to the url we passed into it’s parameters. Once this connection is established, you can use the read() method to return the source code of that url.
import urllib.request
with urllib.request.urlopen('http://wikipedia.org/') as response:
resp = response.read()
print(resp)
We call the return object from the urlopen function the “response” object.
Having the entire source of a URL returned is pretty messy due to how large it is. You’ll have to use something like JSON, regular expressions, or BeautifulSoup to narrow down the information you need.
However we still aren’t done yet. If you examine the output closely, you’ll notice a small “b” at the start, as shown in the image below.
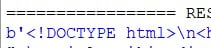
This is because it’s been returned in binary format. We need to decode it back into a string format to use it properly. For this we use the decode method with format of utf-8, which is used widely across the internet.
import urllib.request
with urllib.request.urlopen('http://wikipedia.org/') as response:
resp = response.read().decode("utf-8")
print(resp)
Once you use the read() method on the response object, you can’t do it a second time. This is because Python closes the connection after the first read.
There are alot of other things this response object can tell us, such as the status of the connection. You can’t always expect the connection to succeed after all (connection and availability issues). Using the code attribute, you can return the status type.
>>> response.code
200
Anything within the 200 range stands for a successful connection. The 300 range is for redirects, and the 400 range is for unsuccessful connections. You can check out a full list of status codes here.
You can also try printing response.length to display the size of the code in the response object.
Urllib Parse
This is the Urllib module in charging of parsing the URL once it has been opened. You can choose from a variety of functions to either split the URL into smaller components, or combine smaller components into a complete URL.
There are many parts to a URL besides the name of website. You’ll see that in the example below once we break up the URL.
from urllib.parse import urlparse
url = urlparse("https://en.wikipedia.org/wiki/Hurricane_Laura#Preparations")
print(url)
print(url.scheme)
print(url.fragment)
You access each individual element as well using the format we just showed you above. We didn’t have any search parameters or queries though, so those are empty.
ParseResult(scheme='https', netloc='en.wikipedia.org', path='/wiki/Hurricane_Laura', params='', query='', fragment='Preparations')
https
PreparationsUsing the urlencode you can combine together several parameters together to form a proper query string. The query string will vary a bit from website to website of course.
The below query string has parameters for time and video number, because youtube is a site where you can videos.
import urllib.parse
url = "https://www.youtube.com/watch?"
params = {"v" : "C0DPdy98e4c", "t" : "0m10s"}
query = urllib.parse.urlencode(params)
url = url + query
print(url)
https://www.youtube.com/watch?v=C0DPdy98e4c&t=0m10sSome things will always be consistent though. For example, the query string begins after the ? in the URL. Also the parameters are separated by the & character.
Urllib Error
This is the Urllib module incharge of handling any errors or “exceptions” that may occur during the parsing or fetching of URLs. There are two types of errors that could possible occur.
- The URLError is raised because there is no network connection, or the specified server doesn’t exist.
- The HTTPError occurs in special situations such as authentication request errors. Errors like 404 (page not found) and 401 (authentication required) fall under this category.
URL Error example
The below code will return an error, because a website with that name doesn’t exist.
import urllib.request
import urllib.error
try:
urllib.request.urlopen('http://example_server.com')
except urllib.error.URLError as e:
print(e.reason)
[Errno 11001] getaddrinfo failedHTTP Error example
The below code will return an error because there exists no page with that name on our site.
import urllib.request
import urllib.error
try:
urllib.request.urlopen('https://coderslegacy.com/nonexistent_page.html')
except urllib.error.HTTPError as e:
print(e.reason)
print(e.code)
Not Found
404This marks the end of the Python Urllib tutorial. Any suggestions or contributions for CodersLegacy are more than welcome. Questions regarding the article content can be asked in the comments section below.
nice work, brief but straight forward