
IMAP stands for Internet Mail Access Protocol. It is an Internet standard protocol used by email clients to retrieve email messages from a mail server. Python has introduced a client side library “imaplib“, used to access and read emails over the IMAP protocol using Python code.
In short, in today’s tutorial we will learn how to access, read and display emails from our email accounts, using a simple program using the Python IMAP Library.
Connect to the IMAP server
The first step is connecting to the IMAP server. To do so, we first need to download and install the imaplib library in Python using pip.
pip install imaplibNext we import the imaplib library into our Python program.
import imaplibGreat, we can now begin setting up our secure connection to our email account.
Using the IMAP4_SSL function, we are going to create our imap object. This object contains various functions, such as the login() function which we will use to achieve our goal of reading emails from our Gmail account.
# create an IMAP4 object with an SSL connection
imap = imaplib.IMAP4_SSL("imap.gmail.com")
Since we are using a Gmail account in this tutorial, we are using the IMAP server name for Gmail. This is the string that is passed into the IMAP4_SSL() function. For a complete list of server names, refer to this page.
# Login to your account
imap.login(email, password)
Now login to your account using your email and password. (Pass them both in as strings). You can also use the getpass() module as a secure way of taking the password as input from the user.
Getting an error? Refer to the next section.
Gmail Account Settings
If you run into an error when attempting to login (it would be strange if you didn’t actually), then you need to change the settings on your Gmail account. Visit this link, and simply click on the option present there. This allows your Python program to access your account.
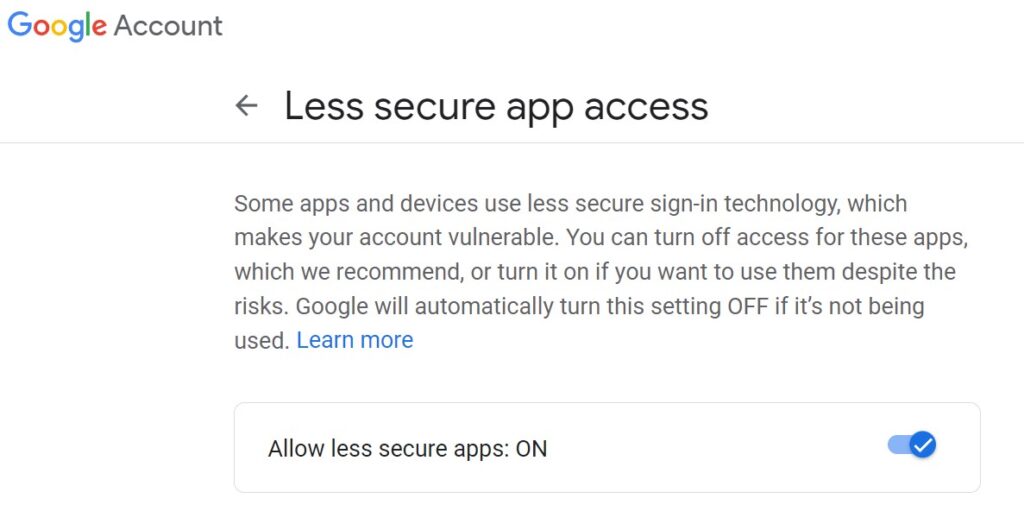
For more information regarding this matter, refer to this page.
Read Emails with imaplib in Python
Now that we have a secure connection setup, let’s begin reading some emails.
We are going to be writing a proper program, which is able to read all kinds of emails. The tricky part with reading emails, is that there are many different scenarios to account for. Such as if an email has an attachment, or whether there is an image displayed in it or maybe some HTML content.
While reading a simple email can be done easily enough, we want to make a program that can handle each scenario. By the end of this tutorial, we will have a program that can:
- Read the text from the email, and display it on the console
- Download attachments from the email
- Display the email and it’s HTML content in the browser
So let’s begin.
import imaplib, email
from email.header import decode_header
import os
import webbrowser
imap = imaplib.IMAP4_SSL("imap.gmail.com") # establish connection
imap.login("[email protected]", "yourpassword") # login
print(imap.list()) # print various inboxes
status, messages = imap.select("INBOX") # select inbox
Here is the base code required to connect to the IMAP server using imaplib. Most of this has already been discussed earlier, but you can see some new imports (which we will use later), and two new lines of code at the end.
The imap.list() function returns a list of all inboxes in your email account, including an custom ones you made. The imap.select() function, is used to select one of these inboxes to extract emails from. We will simply use “INBOX”, which contains all the emails.
Program Structure
Below is the basic skeleton of our IMAP Program. The comments with the <—- —–> indicate there is missing code in those section, that we need to fill out. Once we write all the code, it’s going to be 80+ lines in total, and might be hard to understand in one ago. So we’ve broken this up into several smaller parts, which we will discuss one by one, and fully compile at the end.
numOfMessages = int(messages[0]) # get number of messages
for i in range(numOfMessages, numOfMessages - 3, -1):
res,msg = imap.fetch(str(i), "(RFC822)") # fetches email using ID
for response in msg:
if isinstance(response, tuple):
msg = email.message_from_bytes(response[1])
# <------ Obtain Header (Subject and Sender details) ----->
if msg.is_multipart():
# <------ iterate over each email part ----->
# <------ extract content from email ------>
# <------ Download attachment if found ----->
else: # if there is only one part
# <------ extract content from email ------>
print("-" * 100)
This is the first part of the code. It’s important to understand here, how email ID’s work. If an Inbox has 1000 emails in it, then the ID of the 1000th email is 1000. The ID 1 in this case, will represent the oldest email, and 1000 is the newest. The higher the ID, the newer it is.
numOfMessages = int(messages[0]) # get number of messages
for i in range(numOfMessages, numOfMessages - 3, -1):
res, msg = imap.fetch(str(i), "(RFC822)") # fetches email using ID
for response in msg:
if isinstance(response, tuple):
msg = email.message_from_bytes(response[1])
We have setup the for loop here to read through the 3 newest emails, by beginning from n, where n is the ID of the newest email, and then decrementing. The imap.fetch() function takes an email ID (string), and it returns the email data for the email that matches that ID. "(RFC822)" is the format in which the data is obtained.
This line here, msg = email.message_from_bytes(response[1]), converts the email data which is in byte form, to a proper message object. We will now use this message object to read it’s data and find out more information about the email.
Obtaining Header Information
Now let’s first take a look at obtaining the headers for the email. The Header contains the Sender information and Email subject.
def obtain_header(msg):
# decode the email subject
subject, encoding = decode_header(msg["Subject"])[0]
if isinstance(subject, bytes):
subject = subject.decode(encoding)
# decode email sender
From, encoding = decode_header(msg.get("From"))[0]
if isinstance(From, bytes):
From = From.decode(encoding)
print("Subject:", subject)
print("From:", From)
return subject, From
This function decodes the headers from their byte format (and decodes the subject and from data if nessacery), into regular data (strings). By the end of this, we return the subject and from strings back into the main program after printing them.
Dealing with Multipart Emails
Now it’s time to deal with multipart emails. Emails are quite complex in structure, and can vary greatly based on the contents. A simple email with plain text is a just a single part, whereas emails with more complex data e.g: attachments (images, pdf’s etc.) are comprised of multiparts.
We need to iterate over each one of these parts using the os.walk() function, and obtained the required information from them. We also need to ensure we handle them based of their content type. If an email part consists of an attachment, we will deal with it differently.
.....
if msg.is_multipart():
for part in msg.walk():
content_type = part.get_content_type()
content_disposition = str(part.get("Content-Disposition"))
try:
body = part.get_payload(decode=True).decode()
except:
pass
if content_type == "text/plain" and "attachment" not in content_disposition:
print(body)
elif "attachment" in content_disposition:
download_attachment(part)
else:
content_type = msg.get_content_type()
body = msg.get_payload(decode=True).decode()
if content_type == "text/plain":
print(body)
The get(“Content-Disposition”) and get_content_type() functions give us information about the type of data within that email part. We use this to make decisions, on what we should do. There are three different paths followed in the above code.
if content_type == "text/plain" and "attachment" not in content_disposition:
This if statement will activate if the content type for that email part is just text, and not an attachment. If these two conditions are met, it simply prints out the text.- If the above statement fails, and there is an attachment, then we call the
download_attachment()function. (We will make this function in the next section). - Lastly, if the email wasn’t multipart in the first place, will simply print out the text, just like how we did in case 1.
Downloading Email Attachments with Imaplib
Here we define the download_attachment() function, which takes as parameter, a single email part.
The clean function removes an non-alphanumeric characters which could potentially cause problems when saving the attachment. (There are restrictions on what characters are not allowed in file names on most OS’s)
def clean(text):
# clean text for creating a folder
return "".join(c if c.isalnum() else "_" for c in text)
def download_attachment(part):
# download attachment
filename = part.get_filename()
if filename:
folder_name = clean(subject)
if not os.path.isdir(folder_name):
# make a folder for this email (named after the subject)
os.mkdir(folder_name)
filepath = os.path.join(folder_name, filename)
# download attachment and save it
open(filepath, "wb").write(part.get_payload(decode=True))
What this function does, is that if there is not already a folder with the name of the attachment, it creates that folder. (This check is done to prevent overwriting).
We use the os library frequently here to generate the folder, find the current working directory and generate the filepath where we need to save the attachment. Once we have this filepath, we write the data to that location.
Observing the Results
Now let’s take a look at what we have achieved so far. If we run the following code:
import imaplib
import email
from email.header import decode_header
import os
import webbrowser
imap = imaplib.IMAP4_SSL("imap.gmail.com") # establish connection
imap.login("**********@**********", "**********") # login
#print(imap.list()) # print various inboxes
status, messages = imap.select("INBOX") # select inbox
numOfMessages = int(messages[0]) # get number of messages
def clean(text):
# clean text for creating a folder
return "".join(c if c.isalnum() else "_" for c in text)
def obtain_header(msg):
# decode the email subject
subject, encoding = decode_header(msg["Subject"])[0]
if isinstance(subject, bytes):
subject = subject.decode(encoding)
# decode email sender
From, encoding = decode_header(msg.get("From"))[0]
if isinstance(From, bytes):
From = From.decode(encoding)
print("Subject:", subject)
print("From:", From)
return subject, From
def download_attachment(part):
# download attachment
filename = part.get_filename()
if filename:
folder_name = clean(subject)
if not os.path.isdir(folder_name):
# make a folder for this email (named after the subject)
os.mkdir(folder_name)
filepath = os.path.join(folder_name, filename)
# download attachment and save it
open(filepath, "wb").write(part.get_payload(decode=True))
for i in range(numOfMessages, numOfMessages - 3, -1):
res, msg = imap.fetch(str(i), "(RFC822)") # fetches the email using it's ID
for response in msg:
if isinstance(response, tuple):
msg = email.message_from_bytes(response[1])
subject, From = obtain_header(msg)
if msg.is_multipart():
# iterate over email parts
for part in msg.walk():
# extract content type of email
content_type = part.get_content_type()
content_disposition = str(part.get("Content-Disposition"))
try:
body = part.get_payload(decode=True).decode()
except:
pass
if content_type == "text/plain" and "attachment" not in content_disposition:
print(body)
elif "attachment" in content_disposition:
download_attachment(part)
else:
# extract content type of email
content_type = msg.get_content_type()
# get the email body
body = msg.get_payload(decode=True).decode()
if content_type == "text/plain":
print(body)
print("="*100)
imap.close()
I had three custom emails sent to my email, each being slightly unique. The first being a simple email with text, the second with some special HTML content and the third with an image attachment. Posted below, are screenshots of the email content in the console, and the downloaded attachment on the PC.
Email 1: (Headers + Body printed on Console)

Email 2: (Headers + Body printed on Console)
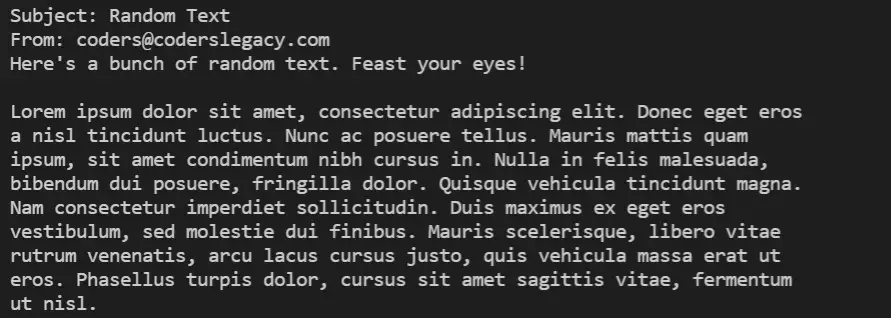
Email 3: (Headers + partial output on console. Full output not included due to size. Just wanted to show you some of the HTML content, which makes no sense on the Console. Until we actually display it on the browser, like we will in the next section)
Interested in learning how to send emails using Python? Check out our tutorial on the SMTP library for more!
Opening HTML Browser (optional)
If you want the HTML content type emails to open up in the browser, we need to define a function for it. If the content_type() functions tells us there is HTML content, we will then run this function.
def open_html(body, subject):
folder_name = clean(subject)
if not os.path.isdir(folder_name):
os.mkdir(folder_name)
filename = "index.html"
filepath = os.path.join(folder_name, filename)
# write the file
open(filepath, "w").write(body)
# open in the default browser
webbrowser.open(filepath)
Most of it is similar to how we did the download_attachment() function. But the slight difference here, is that after saving the HTML content (the body), we display it on the browser using webbrowser module in python.
Where do we call this function? We do it at the very end, right before the print statement that we use to separate emails.
for i in range(numOfMessages, numOfMessages - 3, -1):
res, msg = imap.fetch(str(i), "(RFC822)") # fetches email using ID
for response in msg:
if isinstance(response, tuple):
subject, From = obtain_header(msg)
if msg.is_multipart():
# iterate over email parts
.....
.....
if content_type == "text/html":
# if it's HTML, create a new HTML file and open it in browser
open_html(body, subject)
print("="*100)
imap.close()
The output: (A few screenshots of the emails opened in the browser)

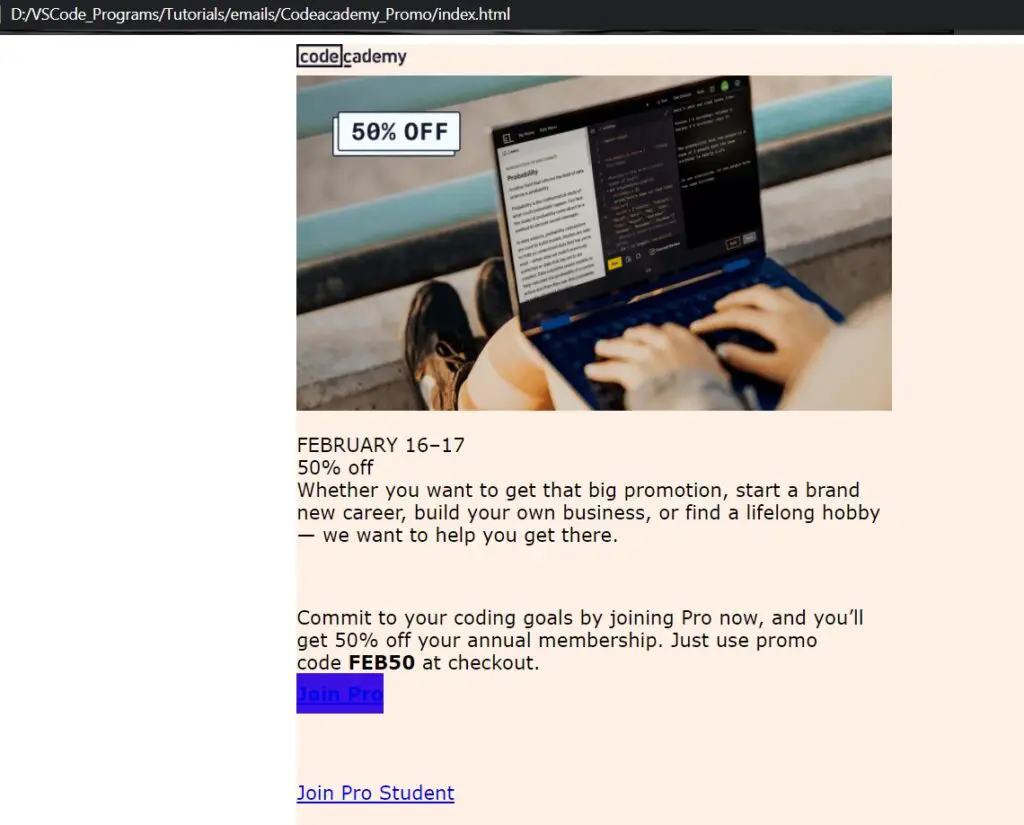
This marks the end of the Python IMAP – Read Emails with imaplib Tutorial. Any suggestions or contributions for CodersLegacy are more than welcome. Questions regarding the tutorial content can be asked in the comments section below.
Thank you
So helpfull! Thanks a lot !
Merci pour votre pédagogie que l’on ne trouve nul par sur le Net.
Vos exemples sont clairs nets et surtout MARCHENT DU PREMIER COUP
VO et MERCI