
Welcome to the Dynamic XPath Tutorial using Selenium. In this tutorial we will explore over 20 different code snippets using XPath commands to retrieve elements from a web page in Selenium.
Prerequisites
The prerequisites to this tutorial is that you have Selenium setup properly on your system. For those who do not, here is a quick briefer on how to setup Selenium easily for use with the Chrome Browser.
First install Selenium and the Webdriver Manager libraries:
pip install selenium
pip install webdriver_managerNext, write the following code into your Python file. All the code that we will write in this tutorial is meant to go where the comment is located.
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium import webdriver
import time
service = ChromeService(executable_path=ChromeDriverManager().install())
options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options = options, service=service)
# CODE HERE
time.sleep(3)
driver.quit()For a full guide on how to setup Selenium (with instructions on other browsers too), please refer to this installation tutorial.
Fetching HTML Data from a Site
Now that we have our Selenium code setup, we will proceed to fetch data from our target site. This will be done using the get() function, which takes the URL of the site as a parameter, in the form of a string.
We will be practicing on the popular practice site (designed for scraping and automation): https://quotes.toscrape.com/
With the following code, we can “get” the required data from this site:
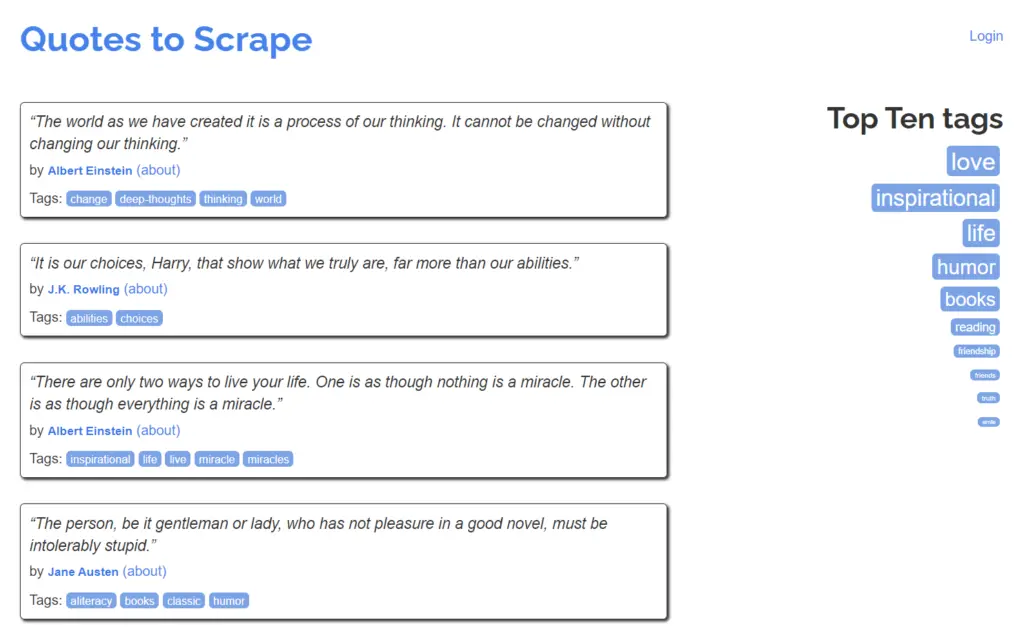
driver.get("https://quotes.toscrape.com/")Here is a picture of the site:
Writing XPath Commands in Selenium
We will be demonstrating over 20 different XPath expressions in this section. For the best possible experience, you should also open up the website in the browser (on desktop), and view the HTML source code side-by-side.
To write an XPath expression, we will use the find_element function, and pass the value By.XPATH into the first parameter. Make sure to setup the correct import for “By” (refer to the setup code at the beginning of the tutorial).
driver.find_element(By.XPATH, "xpath_expression")If we expect to find multiple elements, we will instead use the find_elements function.
driver.find_elements(By.XPATH, "xpath_expression")Xpath expressions begin either a forward slash (“/”) or a double forward slash (“//”). The forward slash (“/”) denotes the root of the document. The double forward slash (“//”) is used to select nodes in the document from the current node, regardless of their location, allowing for more flexible and generalized path expressions.
For example:, this snippet means to find all <a> elements, regardless of their location in the document.
driver.find_elements(By.XPATH, "//a")On the other hand, this means to find all <a> tags located at the very top of the document HTML hierarchy (first level elements).
driver.find_elements(By.XPATH, "/a")Now that we have our concepts covered, we will begin exploring various XPath expressions for the quotes.toscrape website.
Select the Title of the Page:
title_element = driver.find_element(By.XPATH, "//title")
title_text = title_element.get_attribute("innerHTML")HTML Code Snippet where element is located:
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title> <-
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>Access the Login Link:
link_element = driver.find_element(By.XPATH, "//a[text()='Login']")
link_href = link_element.get_attribute("href")HTML Code Snippet where element is located:
...
<div class="col-md-4">
<p>
<a href="/login">Login</a> <--
</p>
</div>
...Find the Text of all Quotes
Using the find_elements function, which returns a list of elements that it found:
quote_elements = driver.find_elements(By.XPATH, "//div[@class='quote']/span[@class='text']")
for quote_element in quote_elements:
quote_text = quote_element.get_attribute("innerHTML")
print(quote_text)Find all details for the first Quote
Here is an interesting concept, where you retrieve an element, then perform further searching on it. Remember to include a “.” in the beginning of the XPath expression when doing this, otherwise it will begin searching through the whole document.
quote = driver.find_element(By.XPATH, "//div[@class='quote'][1]")
quote_text = quote.find_element(By.XPATH,".//span[@class='text']").get_attribute("innerHTML")
quote_author = quote.find_element(By.XPATH, ".//span/small").get_attribute("innerHTML")
quote_tags = quote.find_elements(By.XPATH, ".//div[@class='tags']/a[@class='tag']")
print(quote_text, quote_author, len(quote_tags))HTML structure for the quote element:
...
<div class="quote" itemscope itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world" / >
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
...Find Text of Quote by Albert Einstein
You can use the “..” syntax to go back up a level (similar to how a terminal works when changing directories).
quote = driver.find_element(By.XPATH, "//span/small[@class='author' and text()='Albert Einstein']/../../span[@class='text']")
quote_text = quote.get_attribute("innerHTML")Retrieve All Tag Links:
quotes = driver.find_elements(By.XPATH, "//div[@class='quote']/div[@class='tags']/a[@class='tag']")
for quote in quotes:
print(quote.get_attribute("href"))HTML structure of <div> containing tags (for first quote)
...
<div class="tags">
Tags:
<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world" / >
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
...Retrieve the GoodReads Link in the Footer:
quote = driver.find_element(By.XPATH, "//footer//a[contains(@href,'goodreads.com')]")
link_text = quote.get_attribute("innerHTML")
link_href = quote.get_attribute("href")
print(link_text, link_href)This marks the end of the Selenium Dynamic XPath Tutorial. Any suggestions or contributions for CodersLegacy are more than welcome. Questions regarding the tutorial content can be asked in the comments section below.